


上一篇聊到n8n的10个高阶技巧,想到还有很多小伙伴,对n8n还不够了解,今天再系统的回顾下n8n。
1. 初识 n8n——开启你的自动化之旅
我们将从最基础的概念开始,了解什么是工作流自动化,为什么它对每个人都如此重要,并最终认识我们的主角——n8n。
【简单理解】
你可以把 n8n 想象成”把你会做的数字活儿交给一个勤奋小助理”。它不取代你,而是复制你对流程的理解,持续稳定地替你执行。自动化最适合的任务通常具备3个特征:重复性强、规则明确、跨应用搬运数据。
【真实场景举例】
-
个人场景:把你业务里收到的预定订单带邮箱的人自动加到你的邮件列表,并发一封欢迎邮件。 -
创作者场景:收集某个关键词相关的爆款笔记并二次创作最后同步飞书。 -
小团队场景:每晚汇总当天的订单数据和退款数据,自动生成可视化报表发到 Slack「日报」频道。
【马上动手】 想一件你每周至少做3次、每次超过5分钟的数字操作,写下触发条件(何时发生)、数据来源(在哪儿拿数据)、输出动作(要发到哪里)。后面我们会把它真正自动化起来。
2. 什么是工作流自动化?(为什么你需要它)
想象一下你每天或每周都要处理的那些琐碎、重复的任务:从表格中复制数据粘贴到另一个系统,每次有新客户填写表单后手动发送一封感谢邮件,或者定期整理报告并发送给团队成员。这些任务虽然简单,却耗费了大量宝贵的时间和精力。
工作流自动化就是利用技术来自动执行这些任务或流程,无需人工干预。它就像为你配备了一位不知疲倦的数字助理,严格按照你设定的规则(”如果发生了这件事……”)来执行相应的动作(”……就去做那件事”)。
【深入理解】 “如果发生了这件事→就去做那件事“可以扩展为”如果A且B或C→分别执行X/Y分支”。n8n 支持条件分流和多分支并行。自动化的收益不仅是省时,还包括稳定性(不忘事)、可追溯(每次执行有日志)、可复制(给同事一键复用)。
工作流自动化的核心由两个基本部分组成:
触发器:这是启动一个自动化流程的”事件”。它可以是收到了新邮件、有人提交了表单,甚至是到达了某个预设的时间点(比如每天早上9点)。

动作:这是响应触发器而执行的具体任务。例如更新数据库、发送一条 Slack 消息或在 Google Sheets 中添加新的一行。

【实际业务场景】
-
销售流程:表单来线索→查重→写入CRM→分配销售→建群发首条消息。 -
运营流程:有人购买课程→校验支付→发开课邮件+加群邀请→3天后自动回访问卷。 -
HR流程:候选人投递→解析简历→匹配岗位→安排面试→同步日历并发送候选人确认函。
许多人可能觉得”自动化”是一个非常复杂和遥远的概念,仿佛只存在于大型工厂的生产线上。但实际上,自动化早已融入我们的数字生活。它的真正威力在于,它能充当一座”桥梁”,连接你日常使用的各种应用程序,如 Gmail、Google Sheets、Slack 等,让它们能够互相”沟通”和协作。你已经知道如何使用这些工具,而 n8n 正是那座将它们串联起来、发挥出倍增效应的桥梁。因此,学习自动化并非从零开始,而是为你已有的数字技能锦上添花。
【避坑指南】 从”小闭环”开始(2-3个节点),逐步增加复杂度,避免一上来就做”大而全”的流程导致排错困难。
3. n8n 是什么?(你的新”瑞士军刀”)
n8n 是一款功能强大的低代码自动化工具。你可以把它想象成一把数字世界的”瑞士军刀”,它灵活、强大,能帮你连接不同的应用和服务,构建出属于你自己的自动化工具。
【开源】 开源的价值在于:你能查看节点参数、贡献自定义节点,或请求社区支持;自托管意味着不被某家SaaS限流或涨价”卡脖子”。n8n 既支持”无代码拖拽”,也允许在 Code 节点写 JS/Python,满足从0到1到100的不同层级需求。
与其他自动化工具(如 Zapier 或 Make.com)相比,n8n 拥有几个鲜明的特点,使其脱颖而出:
灵活性与可定制性:n8n 是开源的,这意味着它给予了用户极高的自由度。你可以根据自己的特定需求进行深度定制。
成本效益:特别是对于选择自托管的用户来说,n8n 可以极大地降低自动化工具的使用成本。
数据所有权与隐私:通过自托管,你的所有工作流数据都完全掌握在自己手中,这对于注重数据安全和隐私的个人或企业来说至关重要。
【实际应用场景】
-
混合集成:用官方节点连 Google Sheets;当遇到”没有现成节点”的国产SaaS,立刻用 HTTP Request 节点打通。 -
团队协作:多人协作时,把通用的”清洗地址、手机号校验、发票抬头解析”等做成”子工作流”,各团队共用。
n8n 的设计并不仅仅是提供一个”使用”工具,更是提供一个”创造”平台。它赋予了每个用户成为”构建者”的能力。
4. 如何开始使用 n8n:云端版 vs. 自托管
在你开始构建第一个工作流之前,需要做出一个重要的选择:使用 n8n 官方提供的云端服务,还是在自己的服务器上进行自托管。这两种方式各有优劣,适合不同需求的用户。
【详细对比分析】
云端版:这是最简单快捷的入门方式。n8n 的团队会负责所有的服务器托管和维护工作,你只需注册一个账户,就可以立即开始在网页编辑器中构建工作流。这对于初学者或不希望处理技术细节的小型企业来说是理想的选择。你可以访问 n8n Cloud 注册页面开始使用。
适合云端版的场景:
-
想快点跑起来 -
需要公网回调(Webhook)但不想折腾端口/证书 -
团队成员需要在线协作
自托管:这种方式给予你对 n8n 实例和数据的完全控制权。你可以将其安装在自己的服务器上(使用 Docker 或 Node.js 等方式),并进行深度定制。这需要一定的技术知识来设置和维护,更适合开发者或对数据安全有严格要求的企业。n8n 官方托管指南提供了详细的安装说明。
适合自托管的场景:
-
重隐私合规/内网系统集成 -
需要和私有数据库打通 -
大规模并发任务可控成本
【实际场景对比】
-
云端:市场同学拉通表单→邮件→Slack,一小时上线使用。 -
自托管:把 n8n 部署在公司服务器,打通 ERP/MySQL 内网接口,保证数据不出厂。
为了帮助你做出选择,下面的表格清晰地对比了两种方式的特点:
表 1: n8n 云端版与自托管对比
| 特性 | 云端版 | 自托管 |
|---|---|---|
| 设置难度 | 极简(5分钟注册) | 需要技术配置 |
| 维护成本 | 无需维护 | 需要系统管理 |
| 数据控制 | 托管在n8n服务器 | 完全自控 |
| 成本模式 | 按月付费 | 一次性+服务器费用 |
| 集成能力 | 公网服务优秀 | 内网服务更强 |
| 扩展性 | 受平台限制 | 完全可定制 |
这个选择没有绝对的好坏,关键在于你的需求、技术背景和预算。对于新手,我们强烈建议从 n8n Cloud 开始,这样你可以专注于学习 n8n 本身,而不必为服务器的事情分心。
还有一个方式就是用第三方平台,比如Zeabur,或者clawcloud Run,注册后就可以直接使用里面的n8n了。
【动手操作清单】
-
云端路径:注册 n8n Cloud,创建第一个 Workflow,试试 Manual Trigger + Set 节点。 -
自托管路径:Docker 一键启动;为 Webhook 配置反向代理和 HTTPS(如 Caddy/Nginx),避免第三方回调被拒。
5. 探索 n8n 界面与社区
无论你选择哪种方式,最终都会进入 n8n 的编辑器界面。初次看到可能会觉得有些陌生,但我们可以用一个简单的比喻来理解它的核心元素:
工作流:这就是你的”食谱”。它详细描述了从开始到结束的每一步,定义了整个自动化任务的蓝图。
节点:它们是构成食谱的每一种”食材”和每一个”烹饪步骤”。每个节点都负责执行一项具体任务。
执行:当你的工作流按照触发条件实际运行一次时,就相当于厨房接到了一张”订单”并完成了一道菜。每一次执行都会被记录下来。

【界面导航速成】 3个必逛入口:
-
Nodes(节点库):所有可用的积木块 -
Executions(执行日志):问题排查必看 -
Templates(模板库):学习和快速上手的宝藏




除了强大的工具本身,n8n 还有一个非常活跃和宝贵的资源——它的社区。
官方网址:https://n8n.io/workflows/ 社群网址:https://community.n8n.io/
在社区中,你可以找到大量的预构建工作流模板。这些模板涵盖了各种常见场景,比如”自动发送生日祝福邮件”或”同步 Notion 和 Google Sheets 的数据”。
对于初学者来说,这些模板不仅仅是”快捷方式”,它们更是绝佳的”学习加速器”。当你对如何从一个空白画布开始感到迷茫时,不妨去模板库寻找一个与你目标相似的模板。把它导入到你的工作区,然后像拆解一个玩具一样,仔细研究它的每一个节点是如何连接和配置的。这种”通过解构来学习”的方法,可以让你在实际案例中快速掌握 n8n 的工作原理,是最高效、最没有压力的学习方式之一。
【立即练习】 从模板库挑一个与你最近需求最像的模板,导入后改3件事:触发器、凭证、消息文案。
6. 核心概念——n8n 的基本构建块
在了解了 n8n 的基本情况后,现在让我们深入其内部,掌握构建工作流所必需的核心概念。本章将为你详细解析”节点”的分类、数据在工作流中的”流动”方式,以及如何使用核心节点来处理和转换数据。
理解”节点”:工作流的”积木”
在 n8n 中,节点是构成工作流的最基本单位,就像是搭建模型的”积木”。每一个节点都代表一个特定的任务或操作,比如从 API 获取数据、处理信息或发送邮件。通过将这些节点连接起来,你就定义了自动化流程的顺序和逻辑。
为了方便理解,我们可以将节点分为四大类,每一类都扮演着不同的角色:
1. 触发节点:它们是工作流的起点,告诉 n8n 何时以及如何开始执行。例如,On a schedule(按计划时间触发)或 Webhook(当某个特定网址被访问时触发)。在界面上,它们通常有一个橙色的闪电标志。

常见触发节点类型:
-
Manual Trigger(手动执行) -
Schedule(定时触发) -
Webhook(外部回调) -
App 专用 Trigger(如新邮件到达)
2. 动作节点:它们是工作流中的”实干家”,负责执行具体任务,与外部服务进行交互。例如,Send Email(发送邮件)、Google Sheets(读写谷歌表格)或 Slack(发送消息)。

3. 数据转换节点:它们是数据处理大师,负责在工作流中改变或处理流经它们的数据。例如,Set(设置或修改字段)、Merge(合并来自不同来源的数据)或 Aggregate(将多个数据项聚合为一个)。

4. 逻辑节点:它们是工作流的”决策者”,根据特定条件来控制数据的流向。例如,IF(如果满足条件则走一条路,否则走另一条)或 Switch(根据不同的条件值,将数据分发到多个不同的路径)。

【实际应用场景】
-
订单风控:Webhook 接单→IF 判断是否黑名单→TRUE 走人工复核通知,FALSE 直接发仓→生成快递单。 -
内容管道:RSS→提取正文(HTTP + HTML Extract)→AI 摘要→发布到知识库。
为了让你对常用节点有一个直观的认识,下表汇总了一些最核心的节点及其功能:
表 2: 常用核心节点功能一览
| 节点类型 | 节点名称 | 主要功能 | 使用场景 |
|---|---|---|---|
| 触发 | Manual Trigger | 手动启动工作流 | 测试、一次性任务 |
| 触发 | Schedule Trigger | 定时触发 | 日报、备份、监控 |
| 触发 | Webhook | 接收外部请求 | API集成、表单提交 |
| 动作 | HTTP Request | 调用API | 连接第三方服务 |
| 动作 | Send Email | 发送邮件 | 通知、报告 |
| 动作 | Slack | Slack集成 | 团队协作通知 |
| 数据 | Edit Fields (Set) | 修改/添加字段 | 数据清洗、格式化 |
| 数据 | Code | 自定义代码 | 复杂逻辑处理 |
| 逻辑 | IF | 条件判断 | 分支控制 |
| 逻辑 | Switch | 多条件分流 | 复杂路由 |
【新手易踩坑】 如果有多个输出节点(IF/Switch)连接时要清楚”真/假/分支”的端口,避免路由错乱。
7. 数据的流动与转换:工作流的”血液”
如果说节点是工作流的”器官”,那么数据就是流淌其中的”血液”。理解数据是如何在 n8n 中表示和传递的,是掌握 n8n 的关键所在,也是从简单线性工作流迈向复杂多分支工作流的”万能钥匙”。
在 n8n 中,数据以一种名为 JSON 的格式进行组织和流动。你无需成为 JSON 专家,只需要理解它的基本结构:它是由键值对
例如
{"name": "John",
"age": 30}
组成的集合。每个节点完成任务后,会将其结果(一个或多个 JSON 对象)传递给下一个节点。
【深入理解数据处理】
n8n 每个节点处理的是”Items”数组;绝大多数时候你在看/改的是单个 item 的 json。表达式不只是 ,还能用now、、parameter、、itemIndex;复杂路径优先用方括号安全访问。
那么,我们如何在一个节点中使用前面节点产生的数据呢?答案是表达式。n8n 提供了一种非常直观的方式来使用表达式,你可以把它想象成邮件合并(Mail Merge)功能。你只需将变量名放在双大括号 {{ }} 中,n8n 就会在运行时自动将其替换为真实的数据。

要准确地引用数据,你需要了解两种主要的引用方式:
**相对引用 ($json)**:这是最常用的方式,它代表”来自上一个节点的数据”。例如,在一个发送邮件的节点中,你想使用上一个节点(比如一个表单触发器)传来的用户名,你可以写 {{$json[“customerName”]}}。
**绝对引用 ($node[“NodeName”].json)**:当你的工作流变得复杂,有多个分支时,你可能需要引用并非紧邻的、而是某个特定节点的数据。这时,就需要使用绝对引用。例如,无论当前节点在哪里,你都可以通过 {{$node[“Webhook”].json[“body”][“orderId”]}} 来精确获取名为 “Webhook” 的那个触发器节点收到的订单ID。
掌握这两种引用方式,意味着你拥有了在工作流的任何位置、精确提取任何所需数据的能力。这是构建复杂、强大自动化流程的基础。
【重要提醒】 字段名带空格/中文/符号时,必须用 $json[“字段 名”] 形式;否则运行时报 undefined。
8. 核心数据处理节点详解
现在我们来仔细看看那些负责”改变”数据的核心节点,它们能帮你轻松完成各种”无代码”的数据处理任务。
Edit Fields (Set) Node:数据处理的瑞士军刀
这是最常用的数据处理节点。你可以用它来添加新字段、删除不需要的字段,或者修改现有字段的值。
示例:假设上一个节点传来数据 {“firstName”: “Jane”, “lastName”: “Doe”}。你可以用 Set 节点创建一个新字段 fullName,其值为表达式 {{json[“lastName”]}}。处理后,输出的数据就变成了 {“firstName”: “Jane”, “lastName”: “Doe”, “fullName”: “Jane Doe”}。

Merge Node:数据融合大师
当你有来自两个不同来源的数据需要合并时,这个节点就派上用场了。比如,一个输入是客户的基本信息,另一个输入是该客户的订单列表。Merge 节点可以根据某个共同的键(如客户 ID)将它们合并成一个完整的数据项。

【实际应用】
-
按键合并:Key 为 customerId,把”客户主档”与”最新订单”拼成一条信息 -
按顺序合并:当两路数据一一对应但无共同键(谨慎使用)
Split Out Node:数据拆解器

如果上一个节点传来的是一个包含多个项目的列表(比如一个订单里的多件商品),而你想对每个项目单独进行处理(比如逐个检查库存),Split Out 节点可以帮你把这个列表”拆分”成多个独立的数据项,依次流向下一个节点。
【使用场景】 把订单的 items 数组拆成多个 item,方便逐个调用库存 API。
Aggregate Node:数据聚合专家

这与 Split Out 节点的功能正好相反。当你处理完多个独立的数据项后,可能需要将它们重新”聚合”成一个单一的输出(比如计算总价)。
【聚合功能】
-
统计:sum(price*qty)、count、groupBy(如按品类统计销量)
Code Node:终极武器

这是 n8n 中的”终极武器”。当所有预设的节点都无法满足你复杂的逻辑需求时,你可以使用 Code 节点,用 JavaScript 编写自定义代码来处理数据。对于非程序员来说,这听起来可能很吓人,但这里有一个改变游戏规则的技巧:你可以直接向 ChatGPT 或 Claude 这样的 AI 描述你的需求(例如,”请帮我写一段 JavaScript 代码,计算一个商品数组的总价”),然后将 AI 生成的代码粘贴到 Code 节点中。这使得这个最强大的节点对每个人都触手可及。
【AI 助力编程】 非程序员也能用:让 AI 生成小段 JS,例如”把手机号统一格式化为 +86 开头”。
【动手实践】 构造一个”订单 items → Split Out → HTTP 校验库存 → Aggregate 汇总库存可用率”的小链路。
9. 变量的奥秘:node 及其他
除了流经工作流的数据,n8n 还提供了一些内置的全局变量,它们可以在表达式中随时调用,以获取关于工作流本身或其环境的信息。
表 3: n8n 关键变量速查表
| 变量 | 功能 | 示例 |
|---|---|---|
| $json | 当前节点输入数据 | {{$json.customerName}} |
| $node[“NodeName”] | 指定节点的输出 | {{$node[“Webhook”].json.orderId}} |
| $prevNode | 上一个节点的输出 | {{$prevNode.json.result}} |
| $now | 当前时间 | {{$now.toISO()}} |
| $env | 环境变量 | {{$env.API_KEY}} |
| $parameter | 节点参数 | {{$parameter.apiUrl}} |
| $binary | 二进制文件数据 | {{$binary.attachment}} |
| $itemIndex | 当前项目索引 | {{$itemIndex}} |
【进阶变量技巧】
-
日期处理:{{$now.add({days: 3}).toFormat(“yyyy-LL-dd”)}} -
字符串处理:{$json.note?.replace(/\n/g, ” “) } -
二进制文件:$binary(图片/PDF)
最后,关于访问数据,还需要了解两种语法:点符号和方括号符号。
点符号:当数据字段的名称是简单的、不包含空格或特殊字符时使用。例如:{{$json.customer.name}}。
方括号符号:当字段名称包含空格、特殊字符,或者是一个动态变量时,必须使用方括号。例如:{{$json[“customer name”]}}。
【立即练习】 在 Set 节点新增字段 deliveryDate = {{$now.add({days:2}).toFormat(“yyyy-LL-dd”)}}。
【重要提醒】 复杂表达式建议先在 Expression 编辑器里”预览”,确认不为 undefined/null。
理解这些核心概念,你就拥有了构建 n8n 工作流所需的全部理论知识。接下来,让我们通过一个实战项目来巩固它们!
10. 实战演练——构建你的第一个工作流
理论知识是基础,但只有通过亲手实践,才能真正掌握一门技能。本章将带领你从零开始,一步步构建一个完整、实用的自动化工作流。这个过程不仅能巩固第二章学到的一点核心概念,更重要的是,它将带给你第一次成功创造自动化的喜悦和信心。
项目目标:
我们的项目目标是创建一个工作流,用于”通过NASA获取最近太阳的活动,并生成一份报告”。具体流程如下:
n8n 快速入门:从零开始创建第一个自动化工作流
教程概述
本教程将带你从零开始创建一个完整的 n8n 工作流,通过一个实用的太阳耀斑监控项目,你将掌握以下核心技能:
-
✅ 使用触发器节点启动工作流:学会设置定时触发器 -
✅ 配置 credentials:安全管理 API 密钥 -
✅ 处理数据:使用表达式操作和转换数据 -
✅ 在 n8n 工作流中表示逻辑:实现条件分支 -
✅ 使用 expressions:动态生成内容和引用数据
预期学习成果:完成一个每周自动运行的太阳耀斑监控工作流,根据耀斑级别发送不同的报告。
⏱️ 预计完成时间:10 分钟
先提前把工作流放出来,第一次也可以对照下面教程,看完整工作流是符合配置的,然后再自己亲手搭建。

直接把这段代码,复制粘贴到自己的n8n工作流编排界面。
{
"nodes": [
{
"parameters": {
"resource": "donkiSolarFlare",
"additionalFields": {
"startDate": "={{ $today.minus(7, 'days') }}"
}
},
"type": "n8n-nodes-base.nasa",
"typeVersion": 1,
"position": [
448,
528
],
"id": "6baecf91-36e8-414b-90bb-daf7784fbfbc",
"name": "NASA",
"credentials": {
"nasaApi": {
"id": "5gQeYB8qaSqXm9Kw",
"name": "NASA account"
}
}
},
{
"parameters": {
"resource": "request",
"operation": "send",
"binId": "1765772104088-2706774377729",
"binContent": "=There was a solar flare of class {{$json[\"classType\"]}}",
"requestOptions": {}
},
"type": "n8n-nodes-base.postBin",
"typeVersion": 1,
"position": [
880,
432
],
"id": "bdbef9ac-3fb0-415c-b44f-0061c73032b4",
"name": "PostBin(true)"
},
{
"parameters": {
"resource": "request",
"operation": "send",
"binId": "1765772104088-2706774377729",
"binContent": "=There was a solar flare of class {{$json[\"classType\"]}}",
"requestOptions": {}
},
"type": "n8n-nodes-base.postBin",
"typeVersion": 1,
"position": [
880,
640
],
"id": "7a9764aa-3852-4c0a-a93a-fd73b9f65906",
"name": "PostBin(false)"
},
{
"parameters": {
"content": "## Setup required\n\nYou need to create a NASA account and create credentials, and create a bin with Postbin and enter the ID - see [the documentation](https://docs.n8n.io/try-it-out/longer-introduction/)",
"height": 120,
"width": 600
},
"type": "n8n-nodes-base.stickyNote",
"typeVersion": 1,
"position": [
176,
368
],
"id": "e0114a3e-7698-4572-a20c-1574b8311f23",
"name": "Sticky Note"
},
{
"parameters": {
"rule": {
"interval": [
{
"field": "weeks",
"triggerAtDay": [
1
],
"triggerAtHour": 9
}
]
}
},
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2,
"position": [
224,
528
],
"id": "d9563107-0722-424a-b274-720cfc597953",
"name": "Schedule Trigger1"
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "2f469c8e-12b3-4ee5-95fc-ff81508d0b43",
"leftValue": "={{ $json.classType }}",
"rightValue": "C",
"operator": {
"type": "string",
"operation": "contains"
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.if",
"typeVersion": 2.2,
"position": [
656,
528
],
"id": "d73f3a08-e02a-4cb3-ac79-3df7a68937de",
"name": "If1"
}
],
"connections": {
"NASA": {
"main": [
[
{
"node": "If1",
"type": "main",
"index": 0
}
]
]
},
"Schedule Trigger1": {
"main": [
[
{
"node": "NASA",
"type": "main",
"index": 0
}
]
]
},
"If1": {
"main": [
[
{
"node": "PostBin(true)",
"type": "main",
"index": 0
}
],
[
{
"node": "PostBin(false)",
"type": "main",
"index": 0
}
]
]
}
},
"pinData": {},
"meta": {
"instanceId": "96c9020cef52dd29eeb7178f4445f7210c35e99546ef95ce8674a413e2b80228"
}
}
准备工作:注册 n8n Cloud
本教程使用 n8n Cloud,这是推荐新用户使用的最简单方式:
-
访问 n8n Cloud 注册页面 -
注册免费账户(提供免费试用) -
验证邮箱并完成设置
为什么选择 n8n Cloud?
-
无需安装配置,立即可用 -
自动处理服务器维护 -
适合学习和小型项目
第一步:创建新工作流
1.1 进入工作区
当你打开 n8n 时,先看到概览页面

-
看到工作流列表页面 -
👆 点击 “创建工作流” 按钮
1.2 认识工作流画布
成功创建后,你将看到:
-
🎨 工作流画布:中央的空白区域,用于拖拽和连接节点 -
➕ 添加节点按钮:点击即可搜索和添加功能节点 -
🔧 工具栏:包含保存、测试、激活等功能
💡 初学者提示:
-
工作流画布就像一张白纸,节点是积木块 -
数据从左到右流动,每个节点处理数据并传递给下一个
第二步:添加触发器节点
2.1 理解触发器概念
n8n 提供了两种启动工作流的方式:
-
手动方式:通过点击 “测试工作流” 手动执行 -
自动方式:使用触发器节点,根据外部事件或时间计划自动运行
🎯 教程目标:设置一个每周一早上 9 点自动运行的定时触发器
2.2 添加 Schedule 触发器
操作步骤:
1. 点击 "添加第一步" 按钮
2. 在搜索框输入 "Schedule"
3. 选择 "Schedule Trigger"(计划触发器)
4. 节点将添加到画布并自动打开设置面板

2.3 配置触发时间
在打开的设置面板中,按以下参数配置:
| 参数 | 设置值 | 说明 |
|---|---|---|
| 触发间隔 | 选择 “周” | 按周为单位重复 |
| 触发间隔周数 | 输入 “1” | 每1周执行一次 |
| 工作日触发 | 选择 “星期一” | 在每周一执行 |
| 触发小时 | 选择 “上午9点” | 具体执行时间 |
| 触发分钟 | 输入 “0” | 9点整执行 |
2.4 确认设置
-
📋 检查设置是否正确:每周一上午9:00执行 -
🔄 点击节点外的画布区域关闭设置面板 -
✅ 确认节点显示为橙色图标(表示这是触发器)
🔍 验证要点:
-
触发器节点是工作流的起点,必须首先设置 -
定时触发器适合定期报告、监控、备份等场景
第三步:添加 NASA 节点并设置凭证
3.1 了解 NASA API
项目背景:我们将使用 NASA 的公开 API 获取太阳耀斑数据,这些数据可以帮助了解太阳活动对地球的影响。
API 优势:
-
完全免费 -
数据准确可靠 -
适合学习 API 集成
3.2 添加 NASA 节点
操作步骤:
1. 点击 Schedule 触发器节点右侧的 "+" 连接器
2. 在搜索框输入 "NASA"
3. 选择 "NASA" 节点
4. 在操作列表中搜索并选择 "获取DONKI太阳耀斑报告"
5. 节点添加到画布并自动打开设置面板
🎯 为什么选择太阳耀斑报告?
-
返回结构化的 JSON 数据,便于处理 -
包含分类信息,适合演示条件逻辑 -
数据更新频率适中
3.3 设置 API 凭证
重要概念:凭证(Credentials)是安全访问外部服务的密钥,n8n 提供安全的凭证管理功能。
3.3.1 获取 NASA API 密钥
1. 前往 NASA APIs 网站:https://api.nasa.gov/
2. 找到 "Generate API Key" 链接
3. 填写表单(姓名、邮箱、用途等)
4. 提交后 NASA 将 API 密钥发送到你的邮箱
5. 检查邮箱并复制 API 密钥

3.3.2 在 n8n 中配置凭证
1. 在 NASA 节点设置中,点击 "NASA API 凭证" 下拉菜单
2. 选择 "创建新凭证"
3. 在凭证配置页面:
- API Key 字段:粘贴你的 NASA API 密钥
- 名称:给凭证起个易识别的名字(如 "NASA API - 学习用")
4. 点击 "保存"
5. 关闭凭证界面,确认新凭证已自动选中

🔐 安全最佳实践:
-
永远不要在代码或配置中直接写入密钥 -
为不同环境创建不同的凭证(开发/生产) -
定期轮换 API 密钥
3.4 配置数据时间范围
目标:将默认的30天数据范围缩短为最近7天,提高数据相关性。
3.4.1 添加开始日期字段
1. 在 NASA 节点设置中,点击 "添加字段"
2. 选择 "开始日期"
3. 新字段出现在配置面板中
3.4.2 设置表达式
核心概念:表达式(Expressions)允许你动态生成值,而不是硬编码固定值。
1. 在 "开始日期" 字段旁,点击表达式选项卡(Expression)
2. 点击展开按钮进入完整表达式编辑器
3. 输入以下表达式:
{{ $today.minus(7, 'days') }}
📝 表达式解析:
-
$today:获取当前日期 -
.minus(7, 'days'):减去7天 -
结果:自动生成符合 NASA API 要求的日期格式
3.4.3 验证表达式
-
👀 在表达式编辑器中查看预览结果 -
确认显示的是7天前的正确日期 -
点击 “关闭” 返回节点设置
3.5 测试 NASA 节点
重要步骤:在连接下一个节点之前,务必验证当前节点工作正常。
1. 点击 NASA 节点的 "测试步骤" 按钮
2. n8n 将调用 NASA API 并显示结果
3. 在输出部分查看返回的太阳耀斑数据
4. 确认数据包含 classType 字段(后续步骤需要用到)
✅ 成功标准:
-
节点执行无错误 -
输出显示 JSON 格式的太阳耀斑数据 -
数据时间范围在最近7天内
❌ 故障排除:
-
如果显示认证错误:检查 API 密钥是否正确 -
如果无数据返回:可能近期无太阳耀斑,属正常现象 -
如果格式错误:检查表达式语法
第四步:使用 If 节点添加逻辑
4.1 理解逻辑控制
核心概念:n8n 支持复杂的工作流逻辑,If 节点可以根据条件将数据分流到不同路径。
项目目标:
-
根据太阳耀斑分类级别创建两个分支 -
高级别耀斑(X级)→ 重要警报 -
低级别耀斑(A、B、C、M级)→ 常规报告
4.2 添加 If 节点
操作步骤:
1. 点击 NASA 节点右侧的 "+" 连接器
2. 搜索 "If"
3. 选择 "If" 节点添加到画布
4. 节点自动打开设置面板
4.3 配置判断条件
前提条件:确保你已经运行了 NASA 节点,这样才能在 If 节点中看到可用的数据字段。
4.3.1 设置比较值
| 参数 | 操作 | 说明 |
|---|---|---|
| Value 1 | 从数据面板拖拽 classType 字段 |
太阳耀斑分类级别 |
| 操作类型 | 选择 “字符串 > 包含” | 检查是否包含特定字符 |
| Value 2 | 输入 “X” | X 级是最高级别的太阳耀斑 |
4.3.2 理解太阳耀斑分类
太阳耀斑按强度分为 5 个级别:
-
A 级:最弱的耀斑 -
B 级:弱耀斑 -
C 级:小型耀斑 -
M 级:中等强度耀斑 -
X 级:强耀斑,可能影响地球通信和供电系统
4.4 测试逻辑节点
1. 点击 If 节点的 "测试步骤" 按钮
2. 观察输出面板,查看数据从哪个端口流出:
- True 端口:包含 X 级耀斑的数据
- False 端口:其他级别耀斑的数据
🔍 数据调试技巧:
-
如果最近没有 X 级耀斑,可临时将 Value 2 改为 “M”、”C”、”B” 或 “A” 来测试 -
确认至少有一些数据从某个端口流出
4.5 验证分支逻辑
-
✅ True 分支:应该接收高级别太阳耀斑数据 -
✅ False 分支:应该接收其他级别太阳耀斑数据 -
📊 在输出面板查看每个分支的数据量和内容
第五步:从工作流输出数据
5.1 选择输出方式
项目设计:使用 Postbin 作为数据接收终端,这是一个简单的在线服务,可以接收 HTTP 请求并显示内容。
为什么选择 Postbin?
-
无需注册账户 -
立即可用,便于测试 -
可视化显示接收到的数据
5.2 设置 Postbin
5.2.1 创建 Postbin 容器
1. 访问 https://postb.in/
2. 点击 "Create Bin" 按钮
3. 复制生成的 Bin ID(格式如:1651063625300-2016451240051)
4. 保持浏览器标签页打开,稍后用于查看结果
⏰ 重要提醒:Postbin 容器仅存在 30 分钟,超时需要重新创建。
5.3 添加第一个 PostBin 节点(True 分支)
5.3.1 连接节点
1. 在 If 节点的 True 端口(绿色圆点)上点击 "+" 连接器
2. 搜索 "PostBin"
3. 选择 "PostBin" 节点
4. 选择 "Send Request" 操作
5.3.2 配置基本参数
1. Bin ID 字段:粘贴你的 Postbin ID
2. 确认请求方法为 POST
5.3.3 设置动态内容
核心技能:使用表达式创建包含动态数据的消息。
1. 找到 "Bin Content" 字段
2. 将鼠标悬停在字段上,显示 Expression 选项卡
3. 点击 Expression 选项卡
4. 点击展开按钮进入表达式编辑器
5.3.4 创建高级别警报消息
方法 1:拖拽创建
1. 从 If 节点输出面板拖拽 classType 字段到表达式编辑器
2. 自动生成:{{$json["classType"]}}
3. 在表达式前后添加文本:
发生了一次 级别为 {{$json["classType"]}} 的太阳耀斑 - 这是高级别警报!
方法 2:手工编写
🚨 重要警报:检测到 {{$json["classType"]}} 级太阳耀斑!
时间:{{$json["beginTime"]}}
来源:NASA DONKI 数据
⚠️ 请关注后续太空天气影响

5.3.5 预览和保存
1. 在表达式编辑器中查看预览结果
2. 确认变量被正确替换为实际数据
3. 点击 "关闭" 返回节点配置
4. 关闭 PostBin 节点返回画布
5.4 添加第二个 PostBin 节点(False 分支)
5.4.1 快速复制节点
为了提高效率,我们复制第一个节点:
1. 将鼠标悬停在第一个 PostBin 节点上
2. 点击节点右上角的菜单图标(三个点)
3. 选择 "复制节点" (Duplicate Node)
4. 新节点自动出现在画布上
5.4.2 连接 False 分支
1. 将 If 节点的 False 端口拖拽连接到新的 PostBin 节点
2. 双击新 PostBin 节点打开设置
5.4.3 修改常规报告消息
1. 进入 Bin Content 的表达式编辑器
2. 修改消息内容为:
📊 太阳活动报告:检测到 {{$json["classType"]}} 级太阳耀斑
时间:{{$json["beginTime"]}}
状态:常规监控级别
来源:NASA DONKI 数据
5.5 验证连接
完成后,你的工作流应该有以下结构:
Schedule Trigger → NASA → If Node ┬→ PostBin (True - 高级别)
└→ PostBin (False - 常规)
✅ 检查清单:
-
If 节点有两条出线 -
True 分支连接到第一个 PostBin(高级别警报) -
False 分支连接到第二个 PostBin(常规报告) -
两个 PostBin 节点使用相同的 Bin ID
第六步:测试工作流
6.1 完整测试
现在进行端到端的完整测试:
1. 点击工作流右上角的 "测试工作流" 按钮
2. n8n 开始执行整个工作流
3. 观察每个节点的执行状态:
- 绿色勾号:成功执行
- 红色感叹号:执行错误
- 数字标记:处理的数据项数量
6.2 查看执行结果
6.2.1 在 n8n 中查看
1. 点击每个节点查看输入和输出数据
2. 确认数据正确流向对应的分支
3. 检查表达式是否正确生成消息内容
6.2.2 在 Postbin 中查看
1. 返回 Postbin 浏览器标签页
2. 刷新页面查看接收到的数据
3. 应该看到 1-2 个新的请求记录
4. 点击请求查看具体内容
6.3 测试结果分析
成功示例:
-
Postbin 显示带有太阳耀斑数据的格式化消息 -
消息中的变量被正确替换为实际值 -
分支逻辑正确工作
常见问题及解决:
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 没有数据输出 | 近期无太阳耀斑 | 降低 If 条件标准,改为检查 “M” 级 |
| 变量显示为空 | 字段名错误 | 检查表达式中的字段名是否匹配 |
| Postbin 无记录 | Bin ID 错误或过期 | 重新创建 Postbin 并更新 ID |
| 两个分支都有数据 | If 条件设置错误 | 检查比较操作和判断值 |
6.4 激活工作流
测试成功后,激活工作流使其定期自动运行:
1. 点击工作流右上角的激活开关
2. 开关变为绿色表示已激活
3. 工作流将按照 Schedule 设置自动运行
📅 激活后的行为:
-
每周一上午 9:00 自动执行 -
获取过去 7 天的太阳耀斑数据 -
根据级别发送相应报告到 Postbin
恭喜!你已完成第一个 n8n 工作流 🎉
学习成果回顾
通过本教程,你已经掌握了:
✅ 核心技能
-
触发器配置:设置定时触发器实现自动化 -
凭证管理:安全配置 API 密钥访问外部服务 -
数据处理:使用表达式动态生成内容 -
逻辑控制:通过 If 节点实现条件分支 -
表达式使用:引用数据字段和格式化输出
✅ 工作流架构理解
-
数据从左到右流动的基本原理 -
触发器 → 数据获取 → 逻辑处理 → 输出的标准模式 -
分支控制和多输出处理
✅ 最佳实践应用
-
节点测试的重要性 -
凭证安全管理 -
表达式调试和预览 -
工作流测试和激活流程
完整的工作流架构
你的最终工作流应该如下图所示:
[Schedule Trigger]
↓ (每周一 9:00)
[NASA Node]
↓ (获取太阳耀斑数据)
[If Node]
↓ ↓
True False
↓ ↓
[PostBin] [PostBin]
(高级警报) (常规报告)
扩展学习建议
立即实践:
-
尝试修改触发时间为每日或每小时 -
更改判断条件,观察分支变化 -
添加更多字段到输出消息中
进阶挑战:
-
将 PostBin 替换为发送邮件或 Slack 消息 -
添加数据统计,计算一周内的总耀斑数量 -
实现多级分类(A/B/C/M/X 各一个分支)
深入学习:
-
探索 n8n 模板库,学习更多实用案例 -
了解其他触发器类型(Webhook、邮件监控等) -
学习更高级的数据转换节点
故障排除参考
如果遇到问题:
-
查看执行历史:左侧菜单 → Executions,查看详细错误信息 -
节点调试:点击错误节点,查看输入输出数据 -
重新测试:从有问题的节点开始单独测试 -
检查凭证:确认 API 密钥有效且未过期
常用解决方案:
-
表达式错误:使用表达式编辑器的预览功能 -
连接问题:检查节点间的连接线是否正确 -
数据问题:使用 Set 节点添加调试输出
🎯 下一步:现在你已经具备了构建更复杂工作流的基础!尝试将学到的概念应用到你实际的工作或项目中,这是掌握 n8n 的最佳方式。
完成这个项目,你实践了 n8n 的核心功能,更重要的是,你亲手将一个空白画布变成了一个能为你工作的自动化工具。这种从无到有的创造过程所带来的成就感,将是你继续探索更复杂自动化世界的最大动力。
11. 连接世界——API 与第三方服务集成
当你掌握了 n8n 的基本操作后,你会发现它的真正潜力在于连接万物。n8n 提供了超过 300 个预置的节点,可以轻松连接 Google、Microsoft、Slack 等常用服务。但如果遇到没有预置节点的服务怎么办?
答案是使用 API。本章将为你揭开 API 的神秘面纱,并教你如何使用 n8n 的 HTTP Request 节点这把”万能钥匙”来连接互联网上几乎任何一个开放的服务。
12. API 到底是什么?(餐厅里的秘密)
API (应用程序编程接口) 这个词听起来非常技术化,但我们可以用一个非常生动的”餐厅”比喻来理解它。
想象你走进一家餐厅:
你手中的菜单就是 API。它告诉你这家餐厅能提供什么菜品(服务),以及你需要如何点单(请求格式)。
餐厅厨房里不同的工作台(比如烧烤区、沙拉区)就是 API 端点。每个端点负责处理特定的请求,比如 /users 端点负责处理用户信息,/orders 端点负责处理订单信息。
**你对服务员说”我想要一份牛排,五分熟”**,这个点单的动作本身就是一次 API 调用。
而那位负责在你的餐桌和厨房之间来回传递订单和菜品的服务员,就是 HTTP 请求。他是实现这一切的通信机制。
所以,总结一下:API 就是一份服务清单,而我们通过 HTTP 请求这个”服务员”,向指定的 API 端点”点单”,从而获取服务或数据。这个比喻极大地简化了复杂的概念,让你能直观地理解 n8n 是如何与外部世界进行交互的。
【实际应用场景】
-
天气 API:GET /v3/weather?city=上海 → 返回温度、湿度 → 格式化后发 Slack -
电商平台:POST /orders 创建订单 → 返回 orderId → 后续支付/发货链路继续
13. 使用 HTTP 请求节点:你的万能钥匙
对于那些 n8n 没有提供专用节点的在线服务,只要它提供了 API,我们就可以使用 HTTP Request 节点来与它通信。这个节点就是你的”万能钥匙”。
在 HTTP Request 节点中,最常用的两种请求方法 (Request Method) 是:
GET:从服务器获取 (Get) 数据。这就像你向服务员询问”今天的特色菜是什么?”。你只是在请求信息,而没有改变任何东西。
POST:向服务器提交 (Post) 数据。这就像你告诉服务员”我确定要点这份牛排”,并且附上了你的要求(五分熟)。你正在创建一个新的订单,会改变服务器的状态。
【HTTP 请求通用配置清单】 要使用这个节点,你通常需要做五件事:
-
Method(GET/POST/PUT/PATCH/DELETE) -
URL(基础域名 + 端点) -
Auth & Headers(Content-Type、Authorization) -
Query/Body 参数(JSON 最常见) -
测试一次→观察响应→Set 节点抽取关键字段→下一步节点消费
【重要提醒】
-
Content-Type 与 Body 格式要匹配(application/json + JSON Body);避免 x-www-form-urlencoded 搞混 -
分页 API:记得循环获取(可用 Split In Batches 或 HTTP 的 pagination 选项)
14. 凭证管理:安全地连接你的账户
当你请求一个需要登录才能访问的服务时(比如你的 Google 账户或 Twitter 账户),API 需要一种方式来验证你的身份。这就是凭证的作用。n8n 提供了一个安全的地方来存储这些凭证,这样你就不必在每个工作流中都手动输入它们。
常见的身份验证方式有:
API 密钥:这是最简单的一种方式。服务提供商会给你一个长长的字符串,就像一个特殊的密码。你在每次请求时都带上这个密钥,服务器就知道是你了。
OAuth2:这是一种更安全、更现代的授权机制。它不会直接暴露你的用户名和密码。相反,它会弹出一个授权页面(比如你常见的”使用 Google 账户登录”),在你同意后,服务会给 n8n 一个临时的令牌 (Token) 来访问你的数据。
基本认证:这是一种较老的方式,直接使用用户名和密码进行验证。
【常见鉴权位置】
-
Header:Authorization: Bearer YOUR_TOKEN -
Query:api_key=xxx(不推荐暴露) -
Body:多用于登录交换 token
在 n8n 中,你可以在左侧菜单的 Credentials 部分预先设置好这些凭证。然后在相应的节点中,直接从下拉菜单里选择你已经配置好的凭证即可。这种方式既方便又安全,强烈推荐使用。
【最佳实践】
-
建议每个服务使用”单独凭证”,命名规则:Service-Environment-Owner(如 Slack-Prod-OPS) -
OAuth 回调:自托管时要把回调地址加入提供方白名单(Redirect URI)
【避坑指南】
-
凭证轮换:把到期时间写进节点注释或 Sticky Note,并设提醒 -
不要把密钥硬编码在 Set/Code 节点,统一放 Credentials 或环境变量
【实际应用场景】
-
GitHub OAuth:用于拉 PR 列表、自动评论 -
Google OAuth:读写 Sheets/Calendar
15. 精通工作流——设计、调试与错误处理
构建一个能运行的工作流是第一步,而构建一个稳定、可靠、易于维护的工作流,则是从新手迈向专家的标志。本章将教授你一些高级技巧,包括如何设计高效的工作流、如何像侦探一样调试问题,以及如何建立强大的错误处理机制,让你的自动化系统在面对意外时也能从容应对。
高效工作流的设计原则
一个好的工作流就像一篇结构清晰的文章,逻辑分明,易于阅读和修改。以下是一些关键的设计原则:
保持组织性:为你的节点起一个有意义的名字。例如,不要使用默认的 HTTP Request 2,而是将其重命名为 Get Weather Data。这会让你在几个月后回顾时,能立刻明白每个节点的作用。
模块化与可复用性:如果有一系列节点组合(例如,获取用户信息、格式化姓名、检查会员等级)在多个工作流中都会用到,那么就应该将它创建为一个独立的”子工作流”(Sub-Workflow)。其他工作流可以通过 Execute Workflow 节点来调用它。这就像在编程中编写可复用的函数一样,极大地提高了效率和可维护性。
先规划,后构建:在开始拖拽节点之前,先花几分钟在纸上或白板上画出你的流程图。明确你的目标、触发条件、数据流转路径以及可能出现的异常情况。这会让你在构建过程中思路更清晰,事半功倍。
【设计最佳实践】
-
结构化布局:自左向右、上触发下分支;逻辑节点旁放 Sticky Note 写上”条件A/条件B” -
版本管理:导出 JSON 存 Git;关键流程使用”只读环境”(prod)与”沙箱环境”(staging)
监控与调试:当事情出错时
即使是设计最完美的工作流,也可能因为外部服务的临时故障或数据格式的意外变化而出错。学会如何快速定位和解决问题至关重要。
n8n 提供了强大的工具来帮助你成为一名”工作流侦探”:
执行日志:在 n8n 界面的左侧面板,你可以找到 Executions 选项。这里记录了你所有工作流的每一次运行历史,包括成功和失败的记录。当一个工作流失败时,你可以在这里看到是哪个节点出了错,以及详细的错误信息。这是你排查问题的首要阵地。
调试助手节点:这是一个尚未在官方文档中正式出现,但在社区中广为流传的调试利器。你可以将这个节点插入到工作流的任何两个节点之间,它就像一个”放大镜”,可以清晰地显示流经它的数据到底是什么样的。当你怀疑某个节点输出的数据格式不正确时,可以在它后面接一个 Debug Helper 节点来一探究竟,从而快速定位问题根源。
【问题排查清单】 遇到错误时的标准流程:
-
Executions 看红色节点 -
点开 Error 查看详细信息 -
在出错节点前加 Debug/Set,逐段定位
构建强大的错误处理机制
一个业余的自动化流程在遇到错误时会直接崩溃停止,而一个专业的自动化流程则会预见到错误的可能性,并优雅地处理它。这种从被动响应到主动规划的思维转变,是专业与否的分水岭。n8n 提供了两种层级的错误处理机制:
节点级错误处理(Continue On Fail):
在每个节点的设置 (Settings) 标签页中,你都可以找到一个名为 Continue On Fail 的选项。勾选它之后,即使这个节点在执行时发生错误,整个工作流也不会因此中断,而是会继续向下执行。更棒的是,这个节点的错误信息会从一个特殊的”错误输出”端口(通常是红色的)流出。你可以将这个端口连接到其他节点,比如一个发送邮件的节点,实现在该特定步骤失败时发送警报。
工作流级错误处理:这是更强大、更全局的错误处理方式。你可以创建一个专门用于处理错误的”应急工作流”。这个工作流的触发器选择 Error Trigger。然后,在你任何一个主工作流的设置中,将这个应急工作流指定为它的 Error Workflow。这样一来,无论你的主工作流在哪个节点上因为何种原因失败,n8n 都会自动触发那个应急工作流,并将详细的错误信息(包括哪个工作流、哪个节点、具体错误是什么)传递给它。你可以在应急工作流中设置发送邮件、Slack 消息或短信,从而实现”任何工作流一出错,我立刻收到通知”的专业级监控效果。
【错误处理实例】
-
错误通知:任意节点失败→Error Workflow→发到 #alerts 渠道并附上 execution URL -
重试策略:外部 API 5xx → HTTP 节点 options 启用 retry(指数退避)
【立即实践】 给你的实战工作流增加 Continue On Fail + 错误分支发送通知邮件。
【重要警告】 Continue On Fail 会吞掉异常并继续走主线,务必把”错误输出”接到告警节点,不然悄悄失败。
掌握了这些设计、调试和错误处理的技巧,你构建的就不再是脆弱的”玩具”,而是能够承担关键任务、稳定可靠的自动化系统。
16. 迈向智能——n8n 与 AI Agent
当你已经能够熟练地让不同的应用程序协同工作后,是时候为你的自动化流程注入”智慧”了。本章将带你进入 n8n 与人工智能(AI)结合的前沿领域。我们将了解什么是 AI 代理,以及如何利用 n8n 强大的 AI 集成能力,构建能够思考、分析甚至创造的智能工作流。
AI Agent简介
简单来说,一个人工智能体是一个能够感知其环境、进行决策并自主行动以实现特定目标的软件程序。与传统的”如果这样,就那样”的死板规则不同,AI agent可以理解更复杂的指令,并根据上下文做出合理的判断。
AI 智能体的应用非常广泛,从我们熟悉的智能客服聊天机器人,到能够自动分析海量数据并生成报告的分析师,再到能够帮助程序员编写和调试代码的开发助手。
【AI 应用实例】
-
客服工单摘要:Webhook 收单→LLM 生成”工单摘要+情绪标签”→路由到相应客服组 -
内容排程:RSS 拉文章→LLM 提炼3条社媒文案→Schedule 定时发 Twitter/小红书
在 n8n 中集成 AI
n8n 紧跟 AI 发展的浪潮,内置了众多专门用于与 AI 模型交互的节点,让构建 AI 应用变得前所未有的简单。
其中最核心的 AI 节点包括:
AI Agent Node / Basic LLM Chain:这些是与大型语言模型(LLM,如 OpenAI 的 GPT 系列)进行交互的基础节点。你可以给它一个指令(即”提示词”),它就会返回 AI 生成的文本。
Summarization Chain:专门用于将长篇文章或大量文本浓缩成简洁摘要的节点。
Question and Answer Chain:可以基于你提供的文档或数据,来回答用户提出的相关问题。
要使用这些节点,你通常需要先在相应的 AI 服务提供商(如 OpenAI)网站上注册并获取一个 API 密钥。然后,在 n8n 中配置一个对应的凭证,就可以在 AI 节点中调用它了。
【模型选择指南】
-
总结/改写→小模型快且便宜 -
复杂规划/生成→大模型质量更好
17. 提示词工程入门:如何与 AI 对话
AI 节点本身只是一个工具,其输出结果的质量,在很大程度上取决于你给它的”指令”——也就是提示词 (Prompt)。学习如何编写高质量的提示词,被称为”提示词工程”,这是在 AI 时代一项至关重要的核心技能。
一个好的提示词通常包含以下几个要素:
清晰:明确、毫不含糊地告诉 AI 你想让它做什么。不要说”总结一下”,而要说”请用三个要点来总结下面这篇文章”。
上下文:为 AI 提供背景信息,帮助它更好地理解任务。例如,在提示词开头加上一句”你是一位专业的市场分析师”。
约束:为输出设定规则或限制。例如,”回答请不要超过 100 个字”或”请以 JSON 格式输出结果”。
示例:这是提高 AI 输出准确性的最有效方法之一,也被称为”少样本提示”(Few-shot Prompting)。在你的指令中提供一两个完整的”问题-答案”范例,AI 就能更好地模仿你想要的格式、语气和结构。
【提示词工程 4 件套】
-
角色设定 -
清晰任务 -
输出格式 -
示例约束
掌握提示词工程,意味着你掌握了与 AI 高效沟通的语言,这将直接决定你的 AI 自动化应用的成败。
18. AI 实战:构建一个简单的文档问答机器人
让我们通过一个当前非常流行的 AI 应用——**RAG (Retrieval-Augmented Generation)**,来体验一下在 n8n 中构建 AI 应用的乐趣。
什么是 RAG?
传统的 AI 模型在回答问题时,有时会”一本正经地胡说八道”,因为它依赖的是其庞大的、但可能已经过时的训练数据。RAG 技术解决了这个问题。它的核心思想是:在回答问题前,AI 不再是凭空”猜测”,而是先从你提供的一个或多个特定文档中检索出最相关的信息,然后再基于这些检索到的、绝对准确的信息来生成答案。这使得 AI 的回答变得有据可依,更加可靠。
什么是向量数据库?
RAG 需要一个高效的方式来存储和检索文档信息。这就是向量数据库的用武之地。你可以把它想象成一个特殊的图书馆,它不是按字母顺序或书名来组织书籍,而是按”含义”来组织。它将文本转换成数字(向量),含义相近的文本在空间中的位置也相近。当你问一个关于”小猫”的问题时,它能迅速找到所有与”猫科动物”、”宠物”等相关的文档,即使这些文档里并没有出现”小猫”这个词。
【RAG 实用技巧】
-
文本切块大小:300-800 字符 -
重叠比例:10-20% -
向量维度:由模型决定
简化版 RAG 工作流构建步骤:
-
加载数据:使用 Read PDF 或类似节点,读取你想要作为知识库的文档。 -
文本分割:使用 Text Splitter 节点,将长文档切分成较小的、有意义的段落。这有助于提高检索的精确度。 -
数据嵌入与存储:使用 Vector Store 相关的节点(如 Pinecone 或 Chroma),配合一个 Embeddings 模型(如 OpenAI 的模型),将分割后的文本块转换成向量并存入向量数据库。这一步通常只需要在知识库更新时执行一次。 -
构建问答链:在另一个工作流中,设置一个接收用户问题的触发器。 -
检索与生成:使用 Retrieval Chain 或 AI Agent 节点。这个节点会自动接收用户问题,将其转换为向量,去向量数据库中检索最相关的文本块,然后将这些文本块和原始问题一起发送给语言模型,让它生成最终的、基于文档内容的答案。
【成本与质量控制】
-
永远要求 AI 以 JSON 返回,并在下游用 Information Extractor/Schema 验证结构,避免”多一逗号”导致失败 -
费用与速率:高频调用要做限流与缓存(如”同一URL 24小时内不重复摘要”)

19. 你的自动化大师之路
恭喜你!从对自动化一无所知,到现在能够亲手构建连接各种应用、处理复杂逻辑甚至集成人工智能的工作流,你已经完成了一次意义非凡的旅程。
让我们回顾一下你所掌握的关键技能:
-
你理解了工作流自动化的核心,并学会了使用 n8n 的”积木”——节点来搭建流程 -
你掌握了 n8n 中数据的流动与转换,学会了使用表达式和核心节点来处理数据 -
你通过实战项目,体验了从零到一构建完整工作流的成就感 -
你揭开了 API 的神秘面纱,获得了使用 HTTP Request 节点连接世界的能力 -
你学会了设计、调试和处理错误,让你的自动化系统变得更加稳定和专业 -
你踏入了人工智能的殿堂,学会了如何通过提示词工程与 AI 对话,并构建智能的 RAG 应用
你的 n8n 大师之路才刚刚开始。接下来,你可以:
马上开始构建:思考一下你自己的工作或生活中有什么可以被自动化的,然后动手去实现它。这是最好的学习方式。
探索高级模板:深入研究 n8n 社区中的复杂模板,学习高手们是如何解决问题的。
尝试新的集成:不断尝试连接新的、你感兴趣的应用和服务。
【进阶行动清单】
-
本周目标:上线1个3节点以内的小流程;记录耗时节省与失败率 -
本月目标:把1个跨团队的流程抽象成”子工作流”,让3位同事复用 -
工具箱清单:常用模板、常用表达式片段、通用错误处理子流程、API 调试脚本
【高级进阶练习】
-
多环境部署:同一工作流在 dev/staging/prod 的连接与凭证分离(用环境变量 + If 节点切换) -
成本与性能:用 Split In Batches 控制并发,长流程拆段用 Webhook/Queue 解耦
最重要的是,请记住 n8n 不仅仅是一个工具,它是一种思维方式——一种不断寻找更优解决方案、用创造力解放生产力的思维方式。现在,你已经掌握了这把强大的瑞士军刀,去尽情地创造、连接和自动化吧!
附录:新手常见问题与速答
Q: 我需要会写代码吗? A: 不需要。90% 场景用拖拽和表达式即可,剩下10%可让 AI 生成小段 JS。
Q: 会不会很贵? A: 云端试用即可;自托管+开源能把成本压到最低。
Q: 出错了怎么排查? A: Executions 看红色节点→点开 Error →在出错节点前加 Debug/Set,逐段定位。
Q: 如何学习更多高级功能? A: 从社区模板库入手,选择与你需求相似的模板进行改造和学习。
通过这份完整的入门指南,相信你已经具备了从零开始构建强大自动化工作流的能力。
最好的学习方式就是实践——现在就开始构建你的第一个真正有用的自动化流程吧!




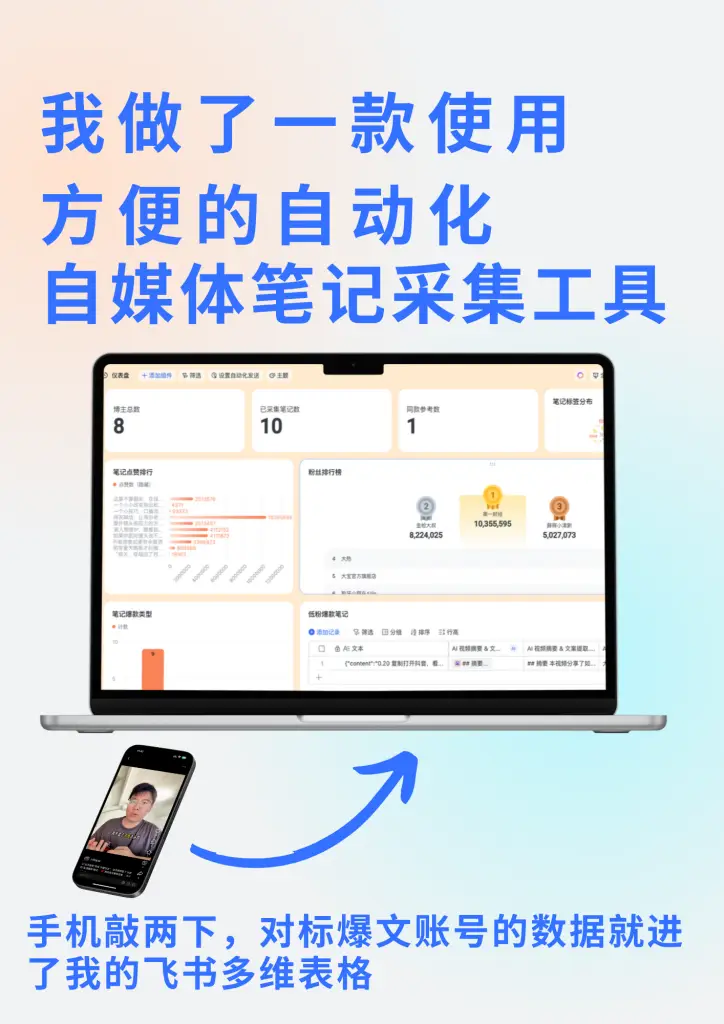



暂无评论内容